반응형
인공신경망(ANN) 모형
- 인공신경망을 이용하면 분류 및 군집을 할 수 있음
- 인공신경망은 입력층, 은닉층, 출력층 3개의 층으로 구성되어 있음
- 각 층에 뉴런(노드)이 여러 개 포함되어 있음
- 학습 : 입력에 대한 올바른 출력이 나오도록 가중치(weight)를 조절하는 것
- 가중치 초기화는 -1.0 ~ 1.0 사이의 임의 값으로 설정하며, 가중치를 지나치게 큰 값으로 초기화하면 활성화 함수를 편향 시키게 되며, 활성화 함수가 과적합 되는 상태를 포화상태라고 함

경하하강법(Gradient descent)
- 함수 기울기를 낮은 쪽으로 계속 이동시켜 극값에 이를 때까지 반복시키는 것
- 제시된 함수의 기울기의 최소값을 찾아내는 머신러닝 알고리즘
- 비용함수(cost function)을 최소하 하기위해 parameter를 반복적으로 조정하는 과정
경사하강법 과정
- 임의의 parameter값으로 시작
- Cost Function 계산, cost function -모델을 구성하는 가중치 w의 함수, 시작점에서 곡선의 기울기 계산
- parameter값 갱신 : W-W-learning rate * 기울기미분값
- n번의 iteration, 최소값을 향해 수렴함, learning rate가 적절해야 함

인공신경망의 모형의 장/단점
신경망 모형의 장점
- 변수의 수가 많거나 입,출력변수 간에 복잡한 비선형 관계에 유용
- 이상치 잡음에 대해서도 민갑하게 반응하지 않음
- 입력변수와 결과변수가 연속형이나 이산형인 경우 모두 처리가능
신경망 모형의 단점
- 결과에 대한 해석이 쉽지 않음
- 최적의 모형을 도출하는 것이 상대적으로 어려움
- 모형이 복잡하면 훈련과정에 시간이 많이 소요됨
- 데이터를 정규화 하지 않으면 지역해(local minimum)에 빠질 위험이 있음

신경망 활설화 함수 17,20,21회 출제
- 결괏값을 내보낼 때 사용하는 함수로, 가중치 값을 학습할 때 에러가 적게 나도록 도움
- 풀고자 하는 문제 종류에 따라 활성화 함수의 선택이 달라짐
- 목표 정확도와 학습시간을 고려하여 선택하고 혼합 사용도함
- 문제 결과가 직선을 따르는 경향이 있으면 '선형함수'를 사용
활성화 함수의 종류

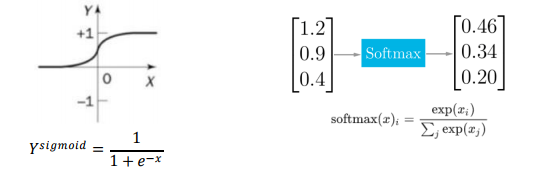
sigmoid함수
- 연속형 0~1,logistic함수라 불리기도 함
- 선형적인 멀티-퍼셉트론에서 비션형 값을 얻기 위해 사용
softmax함수
- 모든 logits의 합이 1이 되도록 output를 정규화
- sigmoid함수의 일반화된 형태로 다 범주인 경우 각 범주에 속할 사후 확률(posterior probabiliby)을 제공하는 활성화 함수
- 주로 3개 이상 분류 시 사용
신경망 은닉층, 은닉노드 17,22,23*2회 출제
- 다중신경망은 단층신경망에 비해 훈련이 어려움
- 은닉층 수와 은닉 노드 수의 결정은 '분석기가 분셕 경험에 의해 설정'함
은닉 층 노드가 너무 적으면
- 네트워크가 복잡한 의사결정 경계를 만들 수 없음
- Underfitting문제 발생
은닉 층 노드가 너무 많으면
- 복잡성을 잡아낼 수 있지만, 일반화가 어렵다
- 레이어가 많아지면 기울기 소실문제가 발생할 수 있다
- 과적합(Overfitting)문제발생
역전파 알고리즘 Backpropagation Algorithm
- 출력층에서 제시한 값에 대해, 실제 원하는 갑승로 학습하는 방법으로 사용
- 동일 입력층에 대해 원하는 값이 출력되도록 개개인의 weight를 조정하는 방법으로 사용됨
기울기 소실 문제 Vanishing Gradient Problem
- 다중 신경망에서 은닉층이 많아 인공신경망 기울기 값을 베이스로 하는 역전파 알고리즘으로 학습 시키려고 할 때 발생하는 문제
기울기 소실
- 역전파(backpropagation)알고리즘은 출력츤(output layer)에서 입력 층(input layer)로 오차 Gradient를 돌려 보내면서, 각 뉴런의 입력 값에 대한 손실함수의 Gradient를 계산함
- 이렇게 계산된 Gradient를 사용하여 각 가중치 매개변수를 업데이트 해줌
- 다중신경망에서는 역전파 알고리즘이 입력층으로 갈수록 Gradient가 점차적으로 작아져 0에 수렴하여, weight가 업데이트가 되지 않는 현상
- activation function으로 sigmoid함수를 사용할 때 발생 -> 해결을 위해 ReL.U등 다른 함수 사용

모형평가
홀드아웃(Hold Out)
- 원천 데이터를 랜덤하게 두 분류로 분리하여 교차검정을 실시하는 방법으로 하나는 모형 학습 및 구축을 위한 훈련용 자료로 다른 하나는 성과평가를 위한 검증용 자료로 사용하는 방법
- 과적합(Overfitting)발생 여부를 확인하기 위해서 주어진 데이터의 일정부분을 모델을 만드는 훈련 데이터로 사용하고, 나머지 데이터를 사용해 모델을 평가
- 잘못된 가설을 가정하게 되는 2종 오류의 발생을 발지
- idx <- sample(2,nrow(iris), replace=TRUE, prob=c(0,7,0,3)) trainData <- iris[idx==1,] testData <- iris[idx==2]
- iris데이터를 7:3비율로 나누어 Training에서 70% Testing에서 30% 사용하도록 하는 것

교자검증(Cross Validation)
- 데이터가 충분하지 않을 경우 hold-out으로 나누면 많은 양의 분산 발생
- 이에 대한 해결책으로 교차검증을 사용할 수 있음, 그러나 클래스 불균형 데이터에는 적합하지 않음
- 주어진 데이터를 가지고 반복적으로 성과를 측정하여 그 결과를 평균한 것으로 분류분석 모형의 평가방법

붓스트랩(Bootstrap)
- 평가를 반복하는 측면에서 교차검증과 유사하지만, 훈련용 자료를 반복 재선정한다는 점에서 차이가 있는 평가방법
- 붓스트랩은 관측치를 한번이상 훈련용 자료로 사용하는 복원추출법에 기반함
- 전체 데이터 양이 크지 않을 경우의 모형 평가에 가장 적합
- 훈련 데이터를 63.2% 사용하는 0.632붓스트랩이 있음
데이터 분할 시 고려사항
- class의 비율이 한쪽에 치우쳐 있는 클래스 불균형 상태라면 다음 기법 사용을 고려한다
- under sampling : 적은 class의 수에 맞추는 것
- over sampling : 많은 class의 수에 맞추는 것

**********오분류표를 활용한 평가지표**********************************33회 출제

정밀도 Precision
- 에측값이 True인 것에 대해 실제값이 True인 지표
- 식 : TP/(TP+FP)
재현율,민감도 Recall,Sensitivity
- 실제값이 True인 것에 대해 에측값이 True인 지표
- 식 : TP/(TP+FN)
F1
- F1은 데이터가 불균형할 때 사용한다
- 오분류표 중 정밀도와 재현율의 조화평균을 나타내며 정밀도와 재현율과 같은 가중치를 부여하여 평균한 지표
- 식 : 2* (Precision * Recall) / ((Precision * Recall)
Accuracy 정분류율
- (TP+TN) / (TP+FP+FN+TN)
- 전체 예측에서 옳은 예측이 비율
Error Rate 오분류율
- (FP+FN) / (TP+FP+FN+TN)
- 전체 예측에서 틀린 예측의 비율
특이도 Specificity
- TN / (TN+FP)
- 실제로 N인 것들 중 예측이 N으로 된 경우의 비율
FP Rate
- FP / (FP+TN), 1 - Specificity
- 실제가 N인데 예측이 P로 된 비율 (Y가 아닌데 Y로 예측된 비율, 1종오류)
kappa
- (Accuracy = P(e)) / (1-P(e)) P(e) : 우연히 일치할 확률
- 두 평가자의 평가가 얼마나 일치하는 지 평가하는 값으로 0~1사이의 값을 가짐
F2
- 재현율에 정밀도의 2배 만큼 가중치를 부여하는 것
************************오분류표 자주 출제되는 방법***********************************

분류모형성능평가
ROC(Receiver Operating Characteristic) Curve
- X축은 FP Rate(1-Specificity),Y축은 민감도(Sensitivity)를 나타내 이 두 평가 값의 관계로 모형을 평가함
- ROC그래프의 밑부분의 면적(AUC,Area Under the Curve)이 넓을수록 좋은 모형으로 평가함
- Recall, Sensitivity : 실제 값이 True인 것에 대해 예측 값이 True로 된 비율, TP/ (TP+FN)
- FP-Rate:FP / (FP+TN),1-Specificity : 실제가 False인데 예측이 True로 된 비율(1종 오류비율)

반응형
'빅데이터분석준전문가자격증' 카테고리의 다른 글
| ADsP. 자주 출제되는 주관식 문제 - PART.1 - 데이터 이해 (0) | 2022.07.04 |
|---|---|
| ADsP. PART.3 - 데이터 분석 - 통계분석 - 정형 데이터 마이닝 (0) | 2022.07.04 |
| ADsP. PART.3 - 데이터 분석 - 통계분석 - 분류(Ciassification)분석 (0) | 2022.07.03 |
| ADsP. PART.3 - 데이터 분석 - 통계분석 - 시계열(time series)분석 (0) | 2022.06.28 |
| ADsP. PART.3 - 데이터 분석 - 통계분석 - 주성분(Principal Component)분석 (0) | 2022.06.28 |